Regularization techniques
Regularization in a Neural Network Explained

In order to understand this topic, you need to be familiar with machine learning basics, and how a neural network works.
Let’s talk about overfitting.
When building a neural network, accuracy is everything, and to have high accuracy, the algorithm needs to be able to work on any set of data, other than the one used in the learning process. Overfitting is what happens when a learning algorithm gets too close or too specific to a certain data set (its training data) and fails to fit additional data (its testing data).

Basically, the model ends up hyper-focusing only on the patterns it can see in the training set, which results in catching noise. noise is the data points that don’t really represent the true properties of the data, but random chance. So in order to prevent the problem of overfitting, we use Regularization. Regularization works on the assumption that smaller weights generate a simpler model. It ‘s a technique used to generalize or to penalize the parameters and thus helps avoid overfitting.
how does penalizing the loss function helps to simplify the model?
On a technical level, regularization is adding a certain term to the cost function to allow us to minimize or more precisely to penalize the weight.
This is the loss function normally as we know it, loss function is the one we use when we compute the gradient descent. by partial derivatives of the cost function with respect to w and b respectively.
keep in mind that for higher accuracy of the model, we need the loss function (also called error function) to be as close to 0 as possible.

the goal here is to shrink the coefficient estimates towards zero. In other words, making our model a less complex and a more flexible one. If we add regularization to our model, we’re essentially trading in some of the ability of our model to fit the training data well for the ability to have the model generalize better to data it hasn’t seen before.
Let’s take the example of L1 regularization, which is one of its most famous techniques.
L1 regularization

follow me on this one, so we have
z(x)= wx + b
right? and then passing it to an activation function let’s take the example of a sigmoid function or a tanh
g(z) = tanh(z)
remember how tanh works ? when z is relatively small, the activation function g(z) acts almost close to a linear function. as for when z is relatively large it acts in a much less linear manner.

so when lambda is large, weights are small, and when weights are small z is small so as if every layer will be roughly linear and if every layer is linear then a whole network is linear. so even a deep network will eventually act like a linear network and will not be able to compute a very non linear complicated decision boundaries that allows it to be very precise and overfit,

L1 regularization is also called Lasso Regression (Least Absolute Shrinkage and Selection Operator), it adds the absolute value of coefficient to the loss function as a penalty term.
if lambda is zero then loss function stays the same . And if lambda is very large, it will add too much weight and it will lead to under-fitting.
underfitting + overfitting = proper fitting
L2 regularization
the L2 regularization adds the squared value of coefficient as penalty term to the loss function. It is also called ridge regression.

The main difference between L1 and L2 is that Lasso shrinks the less important feature’s coefficient to zero therefore, removing the feature completely . while L2 minimizes the value of the irrelevant weights enough too be close to 0 but still exist in the calculation.
In L1 regularization, to minimize the loss function, we try to estimate a value that should lie at the mid of the data distribution. That value will also be the
median of the data distribution mathematically. (The “median” is the “middle” value in the list of numbers). while in L2, while calculating, the loss function in the gradient descent, the loss function tries to minimize the loss by subtracting it from the average of the data distribution.
In a more practical manner, L1 is better than L2 because it helps in feature selection by eliminating the features that are not important. This is helpful when we have a lot of features.
Implementation
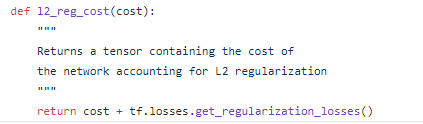
To implement L2 regularization without tensorflow

using Tensorflow:
Dropout
Dropout is the most frequently used regularization technique in the field of deep learning. It randomly selects some nodes and removes them along with all of their incoming and outgoing connections.

How does dropout counts as a regularization technique?
By knocking out units from the network, with every iteration you will be working with a smaller neural network, and so using a smaller network seems like it should have a regularization effect.
This probability of choosing how many nodes should be dropped is the hyperparameter of the dropout function . A network is built dropping out neurons with p probability, therefore keeping the others on with probability
q=1−p
When a neuron is dropped out, its output is set to zero, no matter what the input or the associated learned parameter is. It now does not contribute to the forward nor the backward phases of back-propagation.
how does Dropout work?
Dropout is done by scaling the activation function by a factor of q during the testing phase to use the expected output produced in the training phase as the single output required in the test phase.
The main idea is to randomly drop neurons using Bernoulli gating variables during training so that the network is present with unreliable neurons to prevent co-adaptation among them. Therefore, no neurons depend excessively on other neurons to correct its mistakes and they must work well with other neurons in a wide variety of different situations. The major advantage of dropout allows a single network to be able to model a large number of different sub-networks in an inexpensive and simple means of both training and testing. Experimental results demonstrate that dropout training in a large network not only provides better performance improvement but it is more robust than L2 regularization. In contrast, the L2 regularization yields higher predictive accuracy than dropout in a small network since averaging learning model will enhance the overall performance when the number of sub-model is large and each of them must different from each other.
let’s take the example of just one node in the neural network,

The unit has 4 inputs that needs to eventually generate a meaningful output out of. with dropout, the inputs can be randomly eliminated, which means that this unit can’t rely on any one feature, because any feature could go away at random. So it can’t put all its best on just one input, therefore the unit would be more motivated to spread out the weights and not just focus on one if its input and give a little bit of weight to each of the inputs. by spreading out the weights, this will tend to have an effect of shrinking the squared norm of the weights similarly to L2 regularization. Dropout can be formally shown to be an adaptive form of L2 regularization.
The probability of choosing how many nodes should be dropped is the hyper-parameter of the dropout function. As seen in the image above, dropout can be applied to both the hidden layers as well as the input layers.
Dropout implementation
To create a dropout layer in a Neural Network,

Data augmentation
As we all know, when training a Neural Network, the more the data the better the learning. In a lot of situations we happen to have a small training set, so we try and add more data to our set, however this addition of more data is expensive and costs a lot, Data augmentation is a solution for this problem. It is about creating new data out of the one we already have. how, you ask? simply by making reasonable modifications to data in our training set. this technique is mostly used in visual recognition issues, so we’d flip, rotate, crop, zoom or even vary the color of certain images in the training set

This technique helps improving the accuracy of the model. It can be considered as a mandatory trick when training data is relatively small.
Early stopping
The term is kind of self explanatory, early stopping regularization is basically stopping the learning phase earlier than usual. When plotting the cost function, it would decrease drastically along way with the iteration but at a certain point it will increase back again. Early stopping algorithm stops the training at that exact point.

Whenever we see that the performance of the Neural Network is getting worse, the training is stopped in order to prevent a decrease in performance. although the early stopping algorithm is a good way to prevent performance decrease, a disadvantage of this may be that because the training is stopped early, it does not make use of the entire training data.
That’s it for regularization techniques, if you have any questions or comments please don’t hesitate to leave them here.
for more information, here are a couple of references that helped me understand better